Faster commitment in small Paxos clusters
An alternative message flow for a Paxos cluster that
- can perform cluster-wide commitment in one or two network delays (rather than the usual two or three) for small clusters,
- requires no more message delays than the usual scheme in larger clusters,
- has time-to-cluster-wide-commitment no worse (possibly better) than the usual scheme, and
- may be simpler to implement.
Usual flow
The usual flow of messages in a Paxos protocol is as follows:
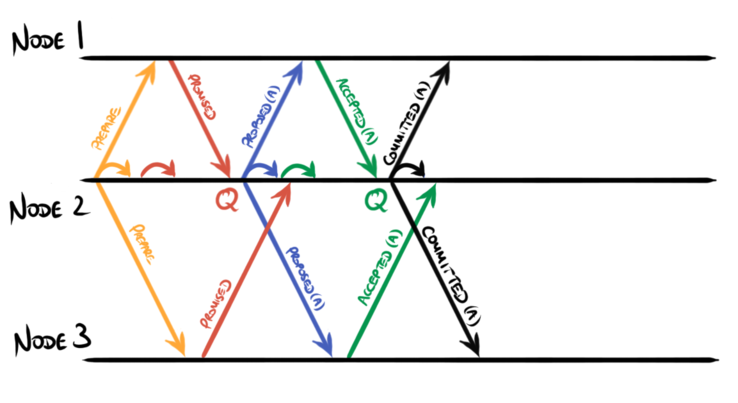
Firstly one of the nodes (node 2 in the diagram) broadcasts a prepare (a.k.a.
phase 1a) message and the other nodes respond with promised (a.k.a. phase 1b)
messages. When a quorum of these has been received, indicated by a Q on the
diagram, the algorithm is said to have completed phase 1 and enters phase 2. In
phase 2 a proposed (a.k.a. phase 2a) message is broadcast and a set of
accepted (a.k.a. phase 2b) messages sent in response. On receipt of a quorum
of acceptances by node 2 the proposed value is chosen and acknowledgements of
this fact can be sent. The other nodes are informed that this value is chosen
by sending a committed message.
The system then remains in phase 2, sending further proposals and acceptances, for an extended period, typically many hours or days until a failure or transmission delay occurs, at which point it returns to phase 1 again:
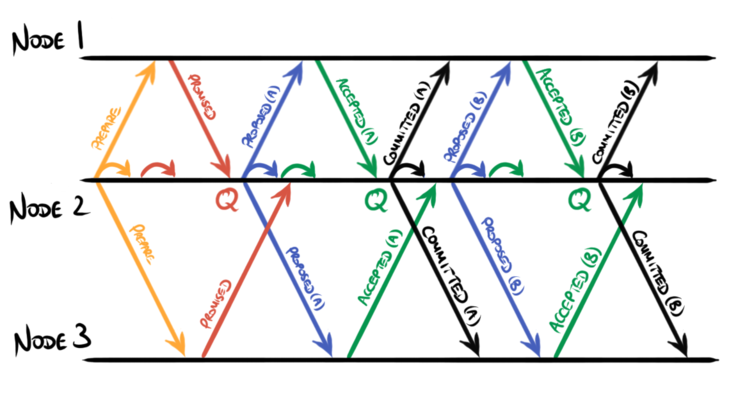
At higher load, writes may be overlapped which allows committed messages to
be combined with subsequent proposed messages:
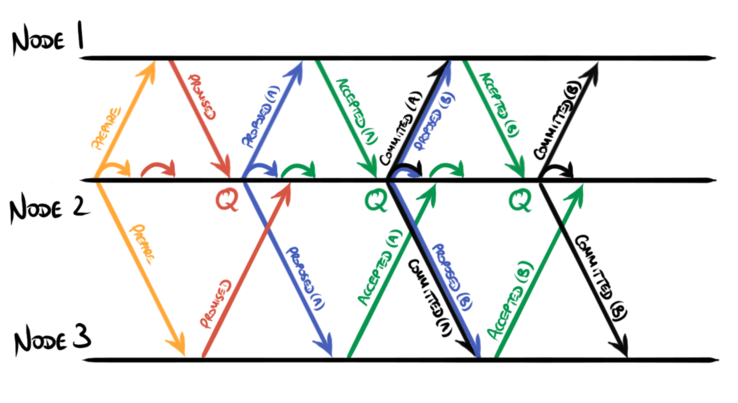
If the writes are more heavily overlapped, it might be that the leader proposes
quite a few values A, B, C, … W, X before achieving quorum on
having written A, so committed(A) ends up getting combined with
proposed(Y).
Avoiding commitment
An alternative scheme is for each acceptor (including the leader) to broadcast
accepted messages to all other nodes on receipt of a proposed message, and
to have each node check for a quorum itself rather than to wait for a
committed message from the leader.
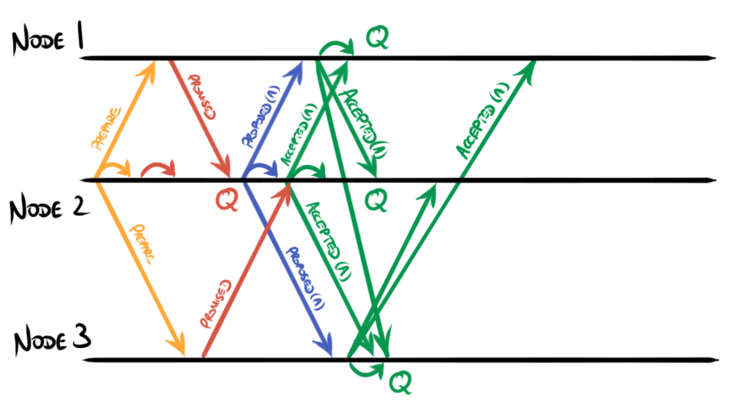
Notice that each node independently achieves quorum (shown as ‘Q’) on the
chosen value on receipt of accepted messages from a majority of its peers.
Since this is a three-node cluster, it only needs a single accepted message,
together with the one it sends itself, to reach quorum. This means there is
no need for the non-proposing nodes to broadcast their accepted messages:
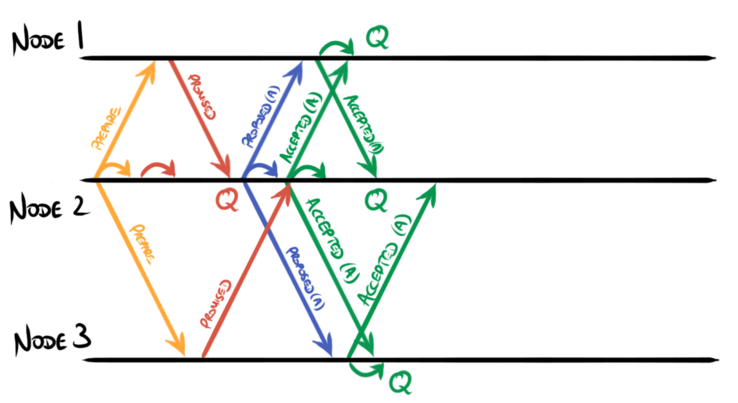
In this scheme the proposed and accepted messages from the leader can
always be combined into a single message, since there is little point in the
leader broadcasting a proposal that it does not itself accept:
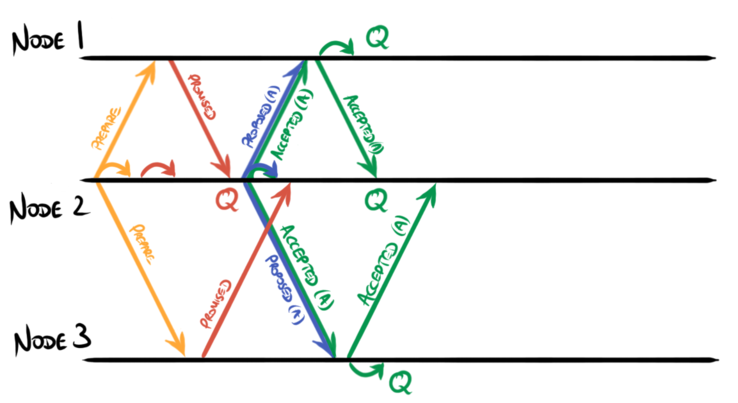
Subsequent proposals follow the same pattern and therefore do not need to
re-enter phase 1. The overall flow of messages is reduced simply to the leader
broadcasting proposed+accepted messages and its followers responding with
accepted messages:
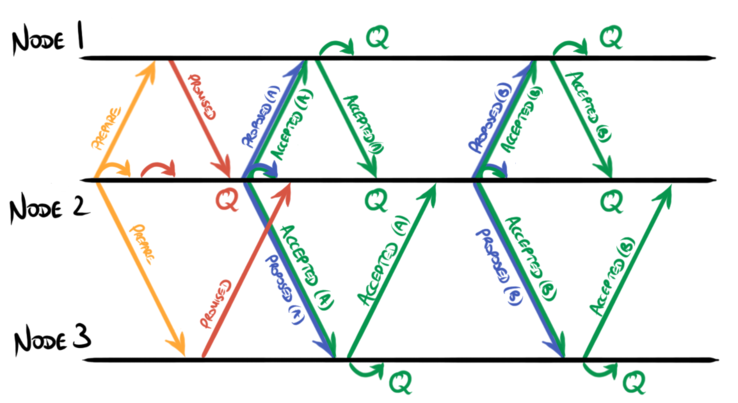
These messages can be overlapped, allowing proposals to be made without waiting for earlier ones to be accepted:
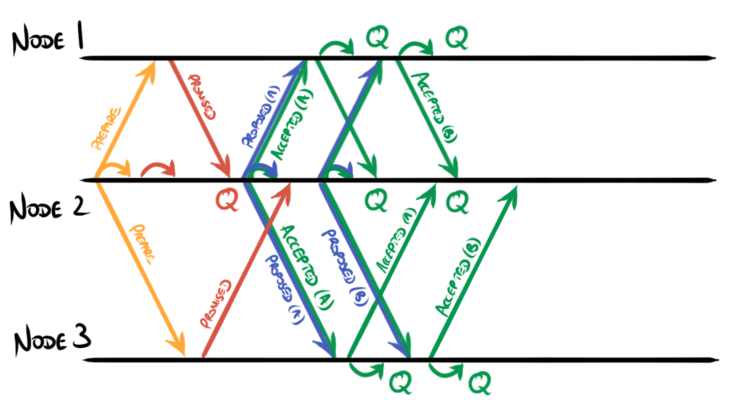
The overall effect is that the leader sends a stream of values (plus a small amount of metadata) to its followers, and the followers respond with a stream of acknowledgements.
Commentary
From implementation experience, I quite like this scheme.
It seems a bit simpler to combine the proposed and accepted messages than
to combine a proposed message with any pending committed messages. The
proposed and accepted messages are for the same slot, generated on the same
code path, whereas in the usual scheme an implementation must check for
committed messages for earlier slots when sending a proposed message. This
means that an implementation of the usual scheme must hold off on sending
committed messages until a proposed message is also ready to send which
adds a delay the the commitment of values across the whole cluster;
implementations must also have a separate mechanism for sending pending
committed messages if there are no proposed messages to send for a period
of time, in order to bound the delay before cluster-wide commitment.
It’s particularly nice for three-node clusters where accepted messages from
the follower nodes don’t need to be broadcast, and the followers learn that
values have been committed after a single message delay. For three-node
clusters this reduces the number of messages required compared with the
standard scheme, but in larger clusters, or during reconfiguration, this
advantage is lost.
Note also that both proposed and committed messages generally carry the
value of the proposal in question, whereas accepted messages do not. If
values are large and the cluster is small then broadcasting accepted messages
could be significantly cheaper than sending each value twice over the wire.
One disadvantage is that if nodes must be able to recover following a crash
(e.g. a power outage) then this scheme requires two durable writes in sequence:
once before the leader sends its proposed+accepted message and a second
before each follower responds with an accepted message. In contrast, if the
leader’s proposed and accepted messages are not combined then it can send
the proposed message, then perform a durable write, and finally send its
accepted message. This issue is also present in Viewstamped Replication
(VR) and the discussion
about it in VR is pertinent here too.